MIT 6.5940 EfficientML.ai Lab 3: Neural Architecture Search
by MIT HAN Lab
Introduction
This colab notebook provides code and a framework for Lab 3: neural architecture search. In this lab, you will learn how to search for a tiny neural network that can run efficiently on a microcontroller. You can work out your solutions here.
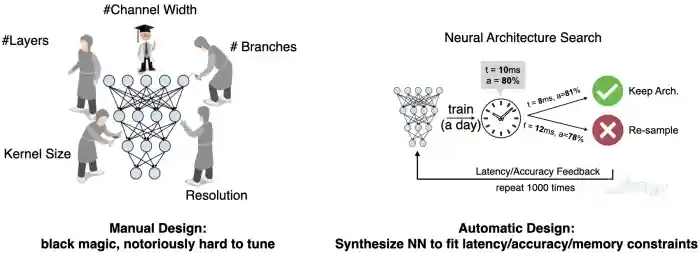
Over a long period of time, researchers manually design neural network architectures. The design space of NN architectures is very large: it includes #layers, #channel width, #branches, kernel sizes and input resolutions. As a result, tuning these design knobs manually is notoriously hard. Neural architecture search, or NAS, on the other hand, can help researchers automatically tune these design knobs under various type of efficiency and accuracy constraints. As a result, it greatly saves engineering cost in NN design and helps democratize AI. In this lab, we are going to walk you through neural architecture search from scratch.
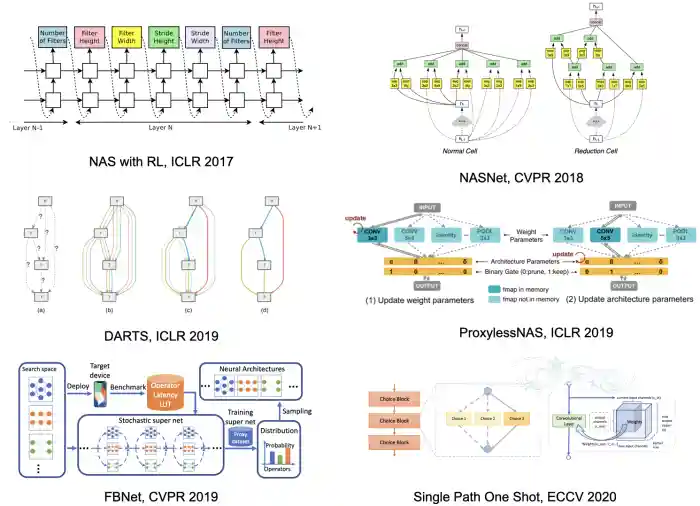
Early NAS methods train candidate network in the design space exhaustively and use RNN-based controllers with reinforcement learning to optimize the sampling strategy. The representative methods include Neural Architecture Search with Reinforcement Learning, NASNet and MNASNet. These methods are usually very computationally expensive because each candidate network has to be trained from scratch such that the RNN-based controller can get the reward signal (which is the accuracy of the candidate network).
Later, researchers develop differentiable NAS methods such as DARTS, ProxylessNAS and FBNet that greatly reduces the total cost of training candidate networks. DARTS model the output of each layer as a weighted average of outputs from different candidate operations, and ProxylessNAS further reduces the memory cost of DARTS by keeping only two paths instead of all paths in the memory. Later one-shot methods such as Single Path One Shot further notice that it is possible to keep only one path at a time during the training process.
Albeit being much more efficient than controller-based methods, differentiable NAS and one-shot NAS still requires running the entire training, search and finetune pipeline everytime we design a new neural network. This brings about large cost (typically 200-300 GPU hours for the ImageNet dataset) for model specialization considering the large amount of edge devices (e.g. there are > 20 billion IoT devices till 2018).
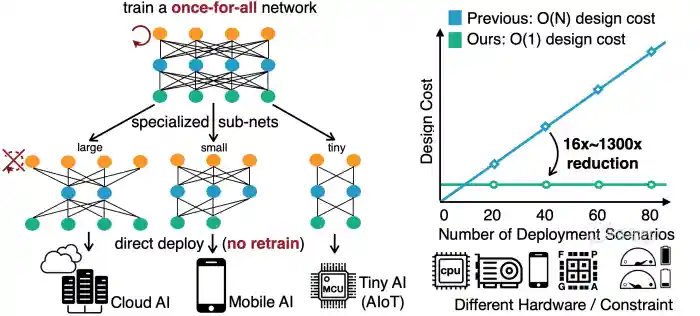
In this lab, we therefore refer to Once for All (OFA), a method that can greatly reduce the cost of specialize NN architectures for different devices. OFA trains a large super network that contains all sub-networks within the design space. If we directly extract the sub-networks from the super network, they can achieve similar-level of accuracy compared with training from scratch. As such, OFA supports direct deployment with no retrain.
Furthermore, OFA introduces accuracy and efficiency predictors to further reduce the evaluation cost during architecture search. Intuitively the accuracy of a sub-network requires running inference on the entire holdout validation set, which can take around 1 minute on ImageNet. OFA, instead, collects a large amount of (architecture, accuracy) pairs beforehand and trains a regression model to predict the accuracy during search. This greatly reduces the cost to get the accuracy feedback from 1 minute to less than 1 second for each sub-network. Similar idea can also be applied to efficiency predictors, where the evaluation of latency are usually very slow since we have to run the forward pass of the candidate network for many times.
In this lab, you will study how to search for efficient networks that can run on extremely resource-constrained microcontrollers with OFA and predictors. Microcontrollers are low-cost, low-power hardware. They are widely deployed and have wide applications.

But the tight memory budget (50,000x smaller than GPUs) makes deep learning deployment difficult.

There are 2 main sections: accuracy & efficiency predictors and architecture search.
- For predictors, there are 4 questions in total. There is one question (5 pts) in the Getting Started section and the other three questions (30 pts) are in the Predictors section.
- For architecture search, there are 6 questions in total.
First, install the required packages and download the Visual Wake Words dataset that will be used in this lab.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # print("Cleanning up workspace ...")
# !rm -rf *
print("Installing graphviz ...")
!sudo apt-get install graphviz 1>/dev/null
print("Downloading MCUNet codebase ...")
!wget https://www.dropbox.com/s/3y2n2u3mfxczwcb/mcunetv2-dev-main.zip?dl=0 >/dev/null
!unzip mcunetv2-dev-main.zip* 1>/dev/null
!mv mcunetv2-dev-main/* . 1>/dev/null
print("Downloading VWW dataset ...")
!wget https://www.dropbox.com/s/169okcuuv64d4nn/data.zip?dl=0 >/dev/null
print("Unzipping VWW dataset ...")
!unzip data.zip* 1>/dev/null
print("Installing thop and onnx ...")
!pip install thop 1>/dev/null
!pip install onnx 1>/dev/null
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| Installing graphviz ...
Downloading MCUNet codebase ...
--2026-05-29 07:13:12-- https://www.dropbox.com/s/3y2n2u3mfxczwcb/mcunetv2-dev-main.zip?dl=0
Resolving www.dropbox.com (www.dropbox.com)... 162.125.81.18, 2620:100:6030:18::a27d:5012
Connecting to www.dropbox.com (www.dropbox.com)|162.125.81.18|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://www.dropbox.com/scl/fi/4fo3qexvbdg47cb7e1mkg/mcunetv2-dev-main.zip?rlkey=241ldxul5ymto3ins60bs3x2m&dl=0 [following]
--2026-05-29 07:13:13-- https://www.dropbox.com/scl/fi/4fo3qexvbdg47cb7e1mkg/mcunetv2-dev-main.zip?rlkey=241ldxul5ymto3ins60bs3x2m&dl=0
Reusing existing connection to www.dropbox.com:443.
HTTP request sent, awaiting response... 302 Found
Location: https://uce2ffe3a4112d0e3bee439b15e3.dl.dropboxusercontent.com/cd/0/inline/DBUpMt5LAfioMYnE8NXg4AXxaOAgP3IRSaLfgQJlKGYLvBZBML4ymKbVGl9g6trf4-p2104PVFNCn2bRiznZvhwMG_l_Ypg8NYEqRA0Vd4QhEePYLD0bCSWWhfWwnWUHSrOrOt9I4Xj7N4mJupaEi_b8/file# [following]
--2026-05-29 07:13:14-- https://uce2ffe3a4112d0e3bee439b15e3.dl.dropboxusercontent.com/cd/0/inline/DBUpMt5LAfioMYnE8NXg4AXxaOAgP3IRSaLfgQJlKGYLvBZBML4ymKbVGl9g6trf4-p2104PVFNCn2bRiznZvhwMG_l_Ypg8NYEqRA0Vd4QhEePYLD0bCSWWhfWwnWUHSrOrOt9I4Xj7N4mJupaEi_b8/file
Resolving uce2ffe3a4112d0e3bee439b15e3.dl.dropboxusercontent.com (uce2ffe3a4112d0e3bee439b15e3.dl.dropboxusercontent.com)... 162.125.81.15, 2620:100:6030:15::a27d:500f
Connecting to uce2ffe3a4112d0e3bee439b15e3.dl.dropboxusercontent.com (uce2ffe3a4112d0e3bee439b15e3.dl.dropboxusercontent.com)|162.125.81.15|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: /cd/0/inline2/DBWl89d8NUNgIONfMj-zs_ivswFzPO9P6kl_UAT5BZ1s3CP9-I0NW-lmMX68toRfrgt6n6WY8DbROlodXDXvCaWr97zrvD8jZ9MsAktLLGagpqxIspS5KcaR2RKkITVJqf_WNhasuwSYrX5K1dwrlU9EkxlSBSp2JlqdoB85RqdOYTdnBtFRsDlzsyMPOz96B75Jlk5MiqcxYPRDYb24dpQbaOshcpI_xZW2hlNEM1gHklA8-17QxsCfKkjJCMctkp_Wv72BG_R2Lo5NRuu3ZVE3wMq1uGpdBAQhOBx8KCwrxrXvwgXfCcOiyDDqtBuflqUoG0mveeMJe1gxgTaZQAxR9j0bzItDUMkm87WQL0I2ls5bZ014NPWD9I69muPxy4w/file [following]
--2026-05-29 07:13:15-- https://uce2ffe3a4112d0e3bee439b15e3.dl.dropboxusercontent.com/cd/0/inline2/DBWl89d8NUNgIONfMj-zs_ivswFzPO9P6kl_UAT5BZ1s3CP9-I0NW-lmMX68toRfrgt6n6WY8DbROlodXDXvCaWr97zrvD8jZ9MsAktLLGagpqxIspS5KcaR2RKkITVJqf_WNhasuwSYrX5K1dwrlU9EkxlSBSp2JlqdoB85RqdOYTdnBtFRsDlzsyMPOz96B75Jlk5MiqcxYPRDYb24dpQbaOshcpI_xZW2hlNEM1gHklA8-17QxsCfKkjJCMctkp_Wv72BG_R2Lo5NRuu3ZVE3wMq1uGpdBAQhOBx8KCwrxrXvwgXfCcOiyDDqtBuflqUoG0mveeMJe1gxgTaZQAxR9j0bzItDUMkm87WQL0I2ls5bZ014NPWD9I69muPxy4w/file
Reusing existing connection to uce2ffe3a4112d0e3bee439b15e3.dl.dropboxusercontent.com:443.
HTTP request sent, awaiting response... 200 OK
Length: 31675052 (30M) [application/zip]
Saving to: ‘mcunetv2-dev-main.zip?dl=0’
mcunetv2-dev-main.z 100%[===================>] 30.21M 13.6MB/s in 2.2s
2026-05-29 07:13:17 (13.6 MB/s) - ‘mcunetv2-dev-main.zip?dl=0’ saved [31675052/31675052]
Downloading VWW dataset ...
--2026-05-29 07:13:18-- https://www.dropbox.com/s/169okcuuv64d4nn/data.zip?dl=0
Resolving www.dropbox.com (www.dropbox.com)... 162.125.81.18, 2620:100:6030:18::a27d:5012
Connecting to www.dropbox.com (www.dropbox.com)|162.125.81.18|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://www.dropbox.com/scl/fi/a2d3mbhj0tn0dfhnojkr6/data.zip?rlkey=oo4sfh74waerp9ub0lecy8u7d&dl=0 [following]
--2026-05-29 07:13:19-- https://www.dropbox.com/scl/fi/a2d3mbhj0tn0dfhnojkr6/data.zip?rlkey=oo4sfh74waerp9ub0lecy8u7d&dl=0
Reusing existing connection to www.dropbox.com:443.
HTTP request sent, awaiting response... 302 Found
Location: https://uc43f5aa2e40d8baeff72b586e14.dl.dropboxusercontent.com/cd/0/inline/DBVzoQ0EEZw3oWOjbMaxjvmfMlusYlUIafr2zCkAaSLgzOL8f6lJcRq1iik3hJdj8QFFIRas8xkm1yaOOOHnXPAXTRqElbGJXEgpNDpMuhK7W67d6XS2J7r14wHjhR3qCTNsn8BKNqaBrA8PDk7-xF2T/file# [following]
--2026-05-29 07:13:20-- https://uc43f5aa2e40d8baeff72b586e14.dl.dropboxusercontent.com/cd/0/inline/DBVzoQ0EEZw3oWOjbMaxjvmfMlusYlUIafr2zCkAaSLgzOL8f6lJcRq1iik3hJdj8QFFIRas8xkm1yaOOOHnXPAXTRqElbGJXEgpNDpMuhK7W67d6XS2J7r14wHjhR3qCTNsn8BKNqaBrA8PDk7-xF2T/file
Resolving uc43f5aa2e40d8baeff72b586e14.dl.dropboxusercontent.com (uc43f5aa2e40d8baeff72b586e14.dl.dropboxusercontent.com)... 162.125.69.15, 2620:100:6025:15::a27d:450f
Connecting to uc43f5aa2e40d8baeff72b586e14.dl.dropboxusercontent.com (uc43f5aa2e40d8baeff72b586e14.dl.dropboxusercontent.com)|162.125.69.15|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: /cd/0/inline2/DBUjuskqW4eHT9cQWv6pT8QMYekVsvYETcRxWO87cyvlt9azKUNt1ddj6WYhlGjvatnejN35om-nmMArddZeDEo2-UF-lqXN2oeBgXV2OlXC-HyXi7IxhLri7VtG_xfRIgmzcVr8UU1nRqssBmwsDTjgwZG-xVt6PPQlItoZ4OKVIirEsncNP_2yJ9LtNXQjr4VBP5ylt5rEpvymX3bxkrebky3nxo8oJtR92WRc9Kzusz826DsoP6jwR8MoX__ibfMnmJU80RLuovnBfNlbfWpSlhJ5NrVxsrx-heecrSfYNh6PE1r-HsvYfXf6id2PCkTnxDLOqQt7KxrXAG3reLr4VdJi5fdY7p6gJQgH1LRLlBzbnbPBhgV4nKCvoe227Ww/file [following]
--2026-05-29 07:13:21-- https://uc43f5aa2e40d8baeff72b586e14.dl.dropboxusercontent.com/cd/0/inline2/DBUjuskqW4eHT9cQWv6pT8QMYekVsvYETcRxWO87cyvlt9azKUNt1ddj6WYhlGjvatnejN35om-nmMArddZeDEo2-UF-lqXN2oeBgXV2OlXC-HyXi7IxhLri7VtG_xfRIgmzcVr8UU1nRqssBmwsDTjgwZG-xVt6PPQlItoZ4OKVIirEsncNP_2yJ9LtNXQjr4VBP5ylt5rEpvymX3bxkrebky3nxo8oJtR92WRc9Kzusz826DsoP6jwR8MoX__ibfMnmJU80RLuovnBfNlbfWpSlhJ5NrVxsrx-heecrSfYNh6PE1r-HsvYfXf6id2PCkTnxDLOqQt7KxrXAG3reLr4VdJi5fdY7p6gJQgH1LRLlBzbnbPBhgV4nKCvoe227Ww/file
Reusing existing connection to uc43f5aa2e40d8baeff72b586e14.dl.dropboxusercontent.com:443.
HTTP request sent, awaiting response... 200 OK
Length: 375960448 (359M) [application/zip]
Saving to: ‘data.zip?dl=0’
data.zip?dl=0 100%[===================>] 358.54M 15.7MB/s in 25s
2026-05-29 07:13:46 (14.5 MB/s) - ‘data.zip?dl=0’ saved [375960448/375960448]
Unzipping VWW dataset ...
Installing thop and onnx ...
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| import argparse
import json
from PIL import Image
from tqdm import tqdm
import copy
import math
import numpy as np
import os
import random
import torch
from torch import nn
from torchvision import datasets, transforms
from mcunet.tinynas.search.accuracy_predictor import (
AccuracyDataset,
MCUNetArchEncoder,
)
from mcunet.tinynas.elastic_nn.networks.ofa_mcunets import OFAMCUNets
from mcunet.utils.mcunet_eval_helper import calib_bn, validate
from mcunet.utils.arch_visualization_helper import draw_arch
%matplotlib inline
from matplotlib import pyplot as plt
import warnings
warnings.filterwarnings('ignore')
|
Getting Started: Super Network and the VWW dataset (1 Question, 5 pts)
In this lab, we will be using the MCUNetV2 super network trained in an once-for-all (OFA) manner. Recall that super network is a randomized large neural network that contains all candidate subnets within the design space. We can directly extract the subnets from the super network and evaluate their accuracy. The accuracy can be further used as a feedback signal to guide neural network design. The advantage of OFA super network is that the directly extracted subnets can achieve similar (or even better) performance compared with training from scratch.
MCUNetV2 is a family of efficiency neural networks tailored for resource-constrained microntrollers. It utilizes patch-based inference, receptive field redistribution and system-NN co-design and greatly improves the accuracy-efficiency tradeoff of MCUNet.
Let’s first visualize some samples in the VWW dataset. This is a binary image classficiation (whether people is present in the image) dataset subsampled from Microsoft COCO. We first define a function to set up a dataloader over the validation set.
Note: The function build_val_data_loader has an argument split. We use split = 0 (default value) to represent the validation set (cannot be directly used for architecture search), and split = 1 will be used as a holdout minival set (used to generate the accuracy dataset and calibrate BN parameters).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| def build_val_data_loader(data_dir, resolution, batch_size=128, split=0):
# split = 0: real val set, split = 1: holdout validation set
assert split in [0, 1]
normalize = transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
kwargs = {"num_workers": min(8, os.cpu_count()), "pin_memory": False}
val_transform = transforms.Compose(
[
transforms.Resize(
(resolution, resolution)
), # if center crop, the person might be excluded
transforms.ToTensor(),
normalize,
]
)
val_dataset = datasets.ImageFolder(data_dir, transform=val_transform)
val_dataset = torch.utils.data.Subset(
val_dataset, list(range(len(val_dataset)))[split::2]
)
val_loader = torch.utils.data.DataLoader(
val_dataset, batch_size=batch_size, shuffle=False, **kwargs
)
return val_loader
|
Using that dataloader builder, we are able to navigate through the VWW validation set. You can run the following cell for several times to see different images in the dataset.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| data_dir = "data/vww-s256/val"
val_data_loader = build_val_data_loader(data_dir, resolution=128, batch_size=1)
vis_x, vis_y = 2, 3
fig, axs = plt.subplots(vis_x, vis_y)
num_images = 0
for data, label in val_data_loader:
img = np.array((((data + 1) / 2) * 255).numpy(), dtype=np.uint8)
img = img[0].transpose(1, 2, 0)
if label.item() == 0:
label_text = "No person"
else:
label_text = "Person"
axs[num_images // vis_y][num_images % vis_y].imshow(img)
axs[num_images // vis_y][num_images % vis_y].set_title(f"Label: {label_text}")
axs[num_images // vis_y][num_images % vis_y].set_xticks([])
axs[num_images // vis_y][num_images % vis_y].set_yticks([])
num_images += 1
if num_images > vis_x * vis_y - 1:
break
plt.show()
|

1
| <Figure size 640x480 with 6 Axes>
|
Cool, now you have a basic idea about the dataset. Let’s then construct the OFA super network! The OFAMCUNets super network is composed of $>10^{19}$ subnets in the MCUNetV2 design space. The subnets are composed of inverted MobileNet blocks with different kernel sizes (3, 5, 7) and expand ratios (3, 4, 6). The OFA super network also allows elastic depths (base depth to base_depth + 2) for all network stages. Finally, the super network supports global channel scaling (specified by width_mult_list) by 0.5$\times$, 0.75$\times$ or 1.0$\times$.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| device = "cuda:0"
ofa_network = OFAMCUNets(
n_classes=2,
bn_param=(0.1, 1e-3),
dropout_rate=0.0,
base_stage_width="mcunet384",
width_mult_list=[0.5, 0.75, 1.0],
ks_list=[3, 5, 7],
expand_ratio_list=[3, 4, 6],
depth_list=[0, 1, 2],
base_depth=[1, 2, 2, 2, 2],
fuse_blk1=True,
se_stages=[False, [False, True, True, True], True, True, True, False],
)
ofa_network.load_state_dict(
torch.load("vww_supernet.pth", map_location="cpu")["state_dict"], strict=True
)
ofa_network = ofa_network.to(device)
|
We then verify that the checkpoint is correctly loaded. We will sample some networks in the MCUNetV2 design space and evaluate its accuracy on the VWW dataset. The evaluation will take less than one minutes, and you are expected to see an accuracy around 83.6-88.7%. As you can see, we can directly extract these subnets from the design space and get their accuracy very quickly without training. This is a unique advantage brought by once-for-all (OFA) super networks.
Let’s first define a helper function evaluate_sub_network that testes the accuracy of a sub network directly extracted from the super network.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| from mcunet.utils.pytorch_utils import count_peak_activation_size, count_net_flops, count_parameters
def evaluate_sub_network(ofa_network, cfg, image_size=None):
if "image_size" in cfg:
image_size = cfg["image_size"]
batch_size = 128
# step 1. sample the active subnet with the given config.
ofa_network.set_active_subnet(**cfg)
# step 2. extract the subnet with corresponding weights.
subnet = ofa_network.get_active_subnet().to(device)
# step 3. calculate the efficiency stats of the subnet.
peak_memory = count_peak_activation_size(subnet, (1, 3, image_size, image_size))
macs = count_net_flops(subnet, (1, 3, image_size, image_size))
params = count_parameters(subnet)
# step 4. perform BN parameter re-calibration.
calib_bn(subnet, data_dir, batch_size, image_size)
# step 5. define the validation dataloader.
val_loader = build_val_data_loader(data_dir, image_size, batch_size)
# step 6. validate the accuracy.
acc = validate(subnet, val_loader)
return acc, peak_memory, macs, params
|
We also provide a handly helper function to visualize the architecture of the subnets. The function takes in the configuration of the subnet and returns an image representing the architecture.
1
2
3
4
5
6
7
8
| def visualize_subnet(cfg):
draw_arch(cfg["ks"], cfg["e"], cfg["d"], cfg["image_size"], out_name="viz/subnet")
im = Image.open("viz/subnet.png")
im = im.rotate(90, expand=1)
fig = plt.figure(figsize=(im.size[0] / 250, im.size[1] / 250))
plt.axis("off")
plt.imshow(im)
plt.show()
|
Now, let’s visualize some subnets and evaluate them on the VWW dataset! We provide an example to randomly sample a subnet from the design space, and get its accuracy, macs, parameters on the VWW dataset. We also visualize the architecture using visualize_subnet.
In the architecture visualization, the legend of each block MBConv{e}-{k}x{k} means that the current block is a mobile inverted block with expand ratio e and the kernel size of the depthwise convolution layer is k. Different colors of the blocks indicate different kernel sizes, and gray blocks are network stage dividers. Different widths for the blocks indicate different expand ratios. We also annotate the output resolution close to each block.
Note that we assume that the image resolution is fixed to be 96. Feel free to add another cell below and play with the input resolution.
Hint: you can change the sample_function argument of the sample_active_subnet method to control the sampling process.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| image_size = 96
cfg = ofa_network.sample_active_subnet(sample_function=random.choice, image_size=image_size)
acc, _, _, params = evaluate_sub_network(ofa_network, cfg)
visualize_subnet(cfg)
print(f"The accuracy of the sampled subnet: #params={params/1e6: .1f}M, accuracy={acc: .1f}%.")
largest_cfg = ofa_network.sample_active_subnet(sample_function=max, image_size=image_size)
acc, _, _, params = evaluate_sub_network(ofa_network, largest_cfg)
visualize_subnet(largest_cfg)
print(f"The largest subnet: #params={params/1e6: .1f}M, accuracy={acc: .1f}%.")
smallest_cfg = ofa_network.sample_active_subnet(sample_function=min, image_size=image_size)
acc, peak_memory, macs, params = evaluate_sub_network(ofa_network, smallest_cfg)
visualize_subnet(smallest_cfg)
print(f"The smallest subnet: #params={params/1e6: .1f}M, accuracy={acc: .1f}%.")
|
1
| Validate: 100%|██████████| 32/32 [00:08<00:00, 3.75it/s, loss=0.325, top1=86.6]
|

1
| <Figure size 1491.6x177.2 with 1 Axes>
|
1
| The accuracy of the sampled subnet: #params= 0.6M, accuracy= 86.6%.
|
1
| Validate: 100%|██████████| 32/32 [00:07<00:00, 4.52it/s, loss=0.29, top1=88.6]
|

1
| <Figure size 1769.2x177.2 with 1 Axes>
|
1
| The largest subnet: #params= 2.5M, accuracy= 88.6%.
|
1
| Validate: 100%|██████████| 32/32 [00:08<00:00, 3.96it/s, loss=0.379, top1=83.4]
|

1
| <Figure size 1075.6x177.2 with 1 Axes>
|
1
| The smallest subnet: #params= 0.3M, accuracy= 83.4%.
|
Question 1 (5 pts): Design space exploration.
Try manually sample different subnets by running the cell above multiple times. You can also vary the input resolution. Talk about your findings.
Hint: which dimension plays the most important role for the accuracy?
Answer: At 96×96 resolution, a random subnet achieved ~86.6% accuracy, the largest subnet ~88.6%, and the smallest ~83.4%. Architecture choices (width, depth, kernel size, expand ratio) still cause a noticeable spread (~5 points), but varying image_size has the largest effect: higher resolution generally improves accuracy at the cost of more MACs and peak activation memory. Among architecture knobs, input image resolution plays the most important role for accuracy.
Part 1. Predictors (3 Questions, 30 pts)
Neural architecture search requires sampling a large amount of sub-networks from the OFA supernet and evaluate the performance of these sub-networks. Such performance evaluation is time-consuming.
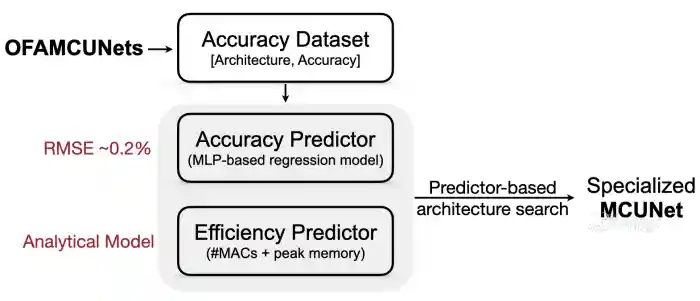
In this lab, we explore very fast neural network search with efficiency predictors and accuracy predictors.
Question 2 (10 pts): Implement the efficiency predictor.
For the efficiency predictor, we use an hook-based analytical model to count the #MACs and peak memory consumption of a given network. Let’s build it from scratch using our provided APIs.
Specifically, we define a class called AnalyticalEfficiencyPredictor. There are two major functions in this class, get_efficiency and satisfy_constraint.
The function get_efficiency takes in the subnet configuration and returns the #MACs and peak memory of the given subnet. Here, we assume the unit for the #MACs is million and the unit of the peak memory consumption is KB.
Hint: take a look at the evaluate_sub_network function above. Let’s use count_net_flops to get the MACs of the network and count_peak_activation_size to get the activation size of the network.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| class AnalyticalEfficiencyPredictor:
def __init__(self, net):
self.net = net
def get_efficiency(self, spec: dict):
self.net.set_active_subnet(**spec)
subnet = self.net.get_active_subnet()
if torch.cuda.is_available():
subnet = subnet.cuda()
############### YOUR CODE STARTS HERE ###############
# Hint: take a look at the `evaluate_sub_network` function above.
# Hint: the data shape is (batch_size, input_channel, image_size, image_size)
data_shape = (1, 3, spec["image_size"], spec["image_size"])
macs = count_net_flops(subnet, data_shape)
peak_memory = count_peak_activation_size(subnet, data_shape)
################ YOUR CODE ENDS HERE ################
return dict(millionMACs=macs / 1e6, KBPeakMemory=peak_memory / 1024)
def satisfy_constraint(self, measured: dict, target: dict):
for key in measured:
# if the constraint is not specified, we just continue
if key not in target:
continue
# if we exceed the constraint, just return false.
if measured[key] > target[key]:
return False
# no constraint violated, return true.
return True
|
Let’s test your implementation for the analytical efficiency predictor by examining the returned values for the smallest and largest subnets we just evaluated a while ago. The results from the efficiency predictor should match with the previous results.
1
2
3
4
5
6
7
8
9
10
11
12
13
| efficiency_predictor = AnalyticalEfficiencyPredictor(ofa_network)
image_size = 96
# Print out the efficiency of the smallest subnet.
smallest_cfg = ofa_network.sample_active_subnet(sample_function=min, image_size=image_size)
eff_smallest = efficiency_predictor.get_efficiency(smallest_cfg)
# Print out the efficiency of the largest subnet.
largest_cfg = ofa_network.sample_active_subnet(sample_function=max, image_size=image_size)
eff_largest = efficiency_predictor.get_efficiency(largest_cfg)
print("Efficiency stats of the smallest subnet:", eff_smallest)
print("Efficiency stats of the largest subnet:", eff_largest)
|
1
2
| Efficiency stats of the smallest subnet: {'millionMACs': 8.302128, 'KBPeakMemory': 72.0}
Efficiency stats of the largest subnet: {'millionMACs': 79.416432, 'KBPeakMemory': 270.0}
|
Question 3 (10 pts): Implement the accuracy predictor.
For the accuracy predictor, it predicts the classification accuracy of a given sub-network on the VWW dataset so that we do NOT need to run costly inference every time when we encounter a new subnet during architecture search. Such an accuracy predictor is an MLP (multi-layer perception) model trained on an accuracy dataset built with the OFA network. The inference of an MLP network takes only a few milliseconds, thus the accuracy predictor can speedup the search process by orders of magnitude.
The accuracy predictor takes in the architecture of a sub-network and predicts its accuracy on the VWW dataset. Since it is an MLP network, the sub-network must be encoded into a vector. In this lab, we provide a class MCUNetArchEncoder to perform such conversion from sub-network architecture to a binary vector.
1
2
3
4
5
6
7
8
| image_size_list = [96, 112, 128, 144, 160]
arch_encoder = MCUNetArchEncoder(
image_size_list=image_size_list,
base_depth=ofa_network.base_depth,
depth_list=ofa_network.depth_list,
expand_list=ofa_network.expand_ratio_list,
width_mult_list=ofa_network.width_mult_list,
)
|
We generated an accuracy dataset beforehand, which is a collection of [architecture, accuracy] pairs stored under the acc_datasets folder.
With the architecture encoder, you are now required define the accuracy predictor, which is a multi-layer perception (MLP) network with 400 channels per intermediate layer. For simplicity, we fix the number of layers to be 3. Please implement this MLP network in the following cell.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| class AccuracyPredictor(nn.Module):
def __init__(
self,
arch_encoder,
hidden_size=400,
n_layers=3,
checkpoint_path=None,
device="cuda:0",
):
super(AccuracyPredictor, self).__init__()
self.arch_encoder = arch_encoder
self.hidden_size = hidden_size
self.n_layers = n_layers
self.device = device
layers = []
############### YOUR CODE STARTS HERE ###############
# Let's build an MLP with n_layers layers.
# Each layer (nn.Linear) has hidden_size channels and
# uses nn.ReLU as the activation function.
# Hint: You can assume that n_layers is fixed to be 3, for simplicity.
# Hint: the input dimension of the first layer is not hidden_size.
# use self.arch_encoder.n_dim to get the input dimension
for i in range(self.n_layers):
layers.append(
nn.Sequential(
nn.Linear(
self.arch_encoder.n_dim if i == 0 else self.hidden_size,
self.hidden_size,
),
nn.ReLU(inplace=True),
)
)
################ YOUR CODE ENDS HERE ################
layers.append(nn.Linear(self.hidden_size, 1, bias=False))
self.layers = nn.Sequential(*layers)
self.base_acc = nn.Parameter(
torch.zeros(1, device=self.device), requires_grad=False
)
if checkpoint_path is not None and os.path.exists(checkpoint_path):
checkpoint = torch.load(checkpoint_path, map_location="cpu")
if "state_dict" in checkpoint:
checkpoint = checkpoint["state_dict"]
self.load_state_dict(checkpoint)
print("Loaded checkpoint from %s" % checkpoint_path)
self.layers = self.layers.to(self.device)
def forward(self, x):
y = self.layers(x).squeeze()
return y + self.base_acc
def predict_acc(self, arch_dict_list):
X = [self.arch_encoder.arch2feature(arch_dict) for arch_dict in arch_dict_list]
X = torch.tensor(np.array(X)).float().to(self.device)
return self.forward(X)
|
Let’s print out the architecture of the AccuracyPredictor you just defined.
1
2
3
4
5
6
7
8
9
10
11
12
| os.makedirs("pretrained", exist_ok=True)
acc_pred_checkpoint_path = (
f"pretrained/{ofa_network.__class__.__name__}_acc_predictor.pth"
)
acc_predictor = AccuracyPredictor(
arch_encoder,
hidden_size=400,
n_layers=3,
checkpoint_path=None,
device=device,
)
print(acc_predictor)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| AccuracyPredictor(
(layers): Sequential(
(0): Sequential(
(0): Linear(in_features=128, out_features=400, bias=True)
(1): ReLU(inplace=True)
)
(1): Sequential(
(0): Linear(in_features=400, out_features=400, bias=True)
(1): ReLU(inplace=True)
)
(2): Sequential(
(0): Linear(in_features=400, out_features=400, bias=True)
(1): ReLU(inplace=True)
)
(3): Linear(in_features=400, out_features=1, bias=False)
)
)
|
Let’s first visualize some samples in the accuracy dataset in the following cell.
The accuracy dataset is composed of 50,000 [architecture, accuracy] pairs, where 40,000 of them are used as the training set and the rest 10,000 are used as validation set.
For accuracy, We calculate the average accuracy of all [architecture, accuracy] pairs on the accuracy dataset and define it as base_acc. For the accuracy predictor, instead of directly regressing the accuracy of each architecture, its training target is accuracy - base_acc. Since accuracy - base_acc is usually much smaller than accuracy itself, this can make training easier.
For architecture, each subnet within the design space is uniquely represented by a binary vector. The binary vector is a concatenation of the one-hot representation for both global parameters (e.g. input resolution, width multiplier) and parameters of each inverted MobileNet block (e.g. kernel sizes and expand ratios). Note that we prefer one-hot representations over numerical representations because all design hyperparameters are discrete values.
For example, our design space supports
1
2
| kernel_size = [3, 5, 7]
expand_ratio = [3, 4, 6]
|
Then, we represent kernel_size=3 as [1, 0, 0], kernel_size=5 as [0, 1, 0], and kernel_size=7 as [0, 0, 1]. Similarly, for expand_ratio=3, it is written as [1, 0, 0]; expand_ratio=4 is written as [0, 1, 0] and expand_ratio=6 is written as [0, 0, 1]. The representation for each inverted MobileNet block is obtained by concatenating the kernel size embedding with the expand ratio embedding. Note that for skipped blocks, we use [0, 0, 0] to represent their kernel sizes and expand ratios. You will see a detailed explanation of the architecture-embedding correspondence after running the following cell.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| acc_dataset = AccuracyDataset("acc_datasets")
train_loader, valid_loader, base_acc = acc_dataset.build_acc_data_loader(
arch_encoder=arch_encoder
)
print(f"The basic accuracy (mean accuracy of all subnets within the dataset is: {(base_acc * 100): .1f}%.")
# Let's print one sample in the training set
sampled = 0
for (data, label) in train_loader:
data = data.to(device)
label = label.to(device)
print("=" * 100)
# dummy pass to print the divided encoding
arch_encoding = arch_encoder.feature2arch(data[0].int().cpu().numpy(), verbose=False)
# print out the architecture encoding process in detail
arch_encoding = arch_encoder.feature2arch(data[0].int().cpu().numpy(), verbose=True)
visualize_subnet(arch_encoding)
print(f"The accuracy of this subnet on the holdout validation set is: {(label[0] * 100): .1f}%.")
sampled += 1
if sampled == 1:
break
|
1
| Loading data: 100%|██████████| 50000/50000 [00:00<00:00, 84005.60it/s]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| Train Size: 40000, Valid Size: 10000
The basic accuracy (mean accuracy of all subnets within the dataset is: 90.3%.
====================================================================================================
network embedding: [0 1 0 0 0 | 1 0 0 | 1 0 0 | 0 0 1 | 1 0 0 | 0 1 0 | 0 1 0 | 1 0 0 | 0 0 1 | 0 0 1 | 0 1 0 | 0 0 1 | 0 0 1 | 0 1 0 | 1 0 0 | 0 1 0 | 1 0 0 | 1 0 0 | 1 0 0 | 1 0 0 | 0 0 0 | 0 0 0 | 0 0 0 | 0 0 0 | 0 0 1 | 0 1 0 | 1 0 0 | 0 0 1 | 0 0 0 | 0 0 0 | 0 0 0 | 0 0 0 | 0 1 0 | 0 1 0 | 0 1 0 | 0 1 0 | 0 0 1 | 0 1 0 | 0 0 0 | 0 0 0 | 0 0 1 | 1 0 0]
image resolution embedding: [0 1 0 0 0] => image resolution: 112
width multiplier embedding: [1 0 0] => width multiplier: 0.5
**************************************************Stage1**************************************************
kernel size embedding: [1 0 0] => kernel size: 3; expand ratio embedding: [0 0 1] => expand ratio: 6
kernel size embedding: [1 0 0] => kernel size: 3; expand ratio embedding: [0 1 0] => expand ratio: 4
kernel size embedding: [0 1 0] => kernel size: 5; expand ratio embedding: [1 0 0] => expand ratio: 3
**************************************************Stage2**************************************************
kernel size embedding: [0 0 1] => kernel size: 7; expand ratio embedding: [0 0 1] => expand ratio: 6
kernel size embedding: [0 1 0] => kernel size: 5; expand ratio embedding: [0 0 1] => expand ratio: 6
kernel size embedding: [0 0 1] => kernel size: 7; expand ratio embedding: [0 1 0] => expand ratio: 4
kernel size embedding: [1 0 0] => kernel size: 3; expand ratio embedding: [0 1 0] => expand ratio: 4
**************************************************Stage3**************************************************
kernel size embedding: [1 0 0] => kernel size: 3; expand ratio embedding: [1 0 0] => expand ratio: 3
kernel size embedding: [1 0 0] => kernel size: 3; expand ratio embedding: [1 0 0] => expand ratio: 3
kernel size embedding: [0 0 0] expand ratio embedding: [0 0 0] => layer skipped.
kernel size embedding: [0 0 0] expand ratio embedding: [0 0 0] => layer skipped.
**************************************************Stage4**************************************************
kernel size embedding: [0 0 1] => kernel size: 7; expand ratio embedding: [0 1 0] => expand ratio: 4
kernel size embedding: [1 0 0] => kernel size: 3; expand ratio embedding: [0 0 1] => expand ratio: 6
kernel size embedding: [0 0 0] expand ratio embedding: [0 0 0] => layer skipped.
kernel size embedding: [0 0 0] expand ratio embedding: [0 0 0] => layer skipped.
**************************************************Stage5**************************************************
kernel size embedding: [0 1 0] => kernel size: 5; expand ratio embedding: [0 1 0] => expand ratio: 4
kernel size embedding: [0 1 0] => kernel size: 5; expand ratio embedding: [0 1 0] => expand ratio: 4
kernel size embedding: [0 0 1] => kernel size: 7; expand ratio embedding: [0 1 0] => expand ratio: 4
kernel size embedding: [0 0 0] expand ratio embedding: [0 0 0] => layer skipped.
**************************************************Stage6**************************************************
kernel size embedding: [0 0 1] => kernel size: 7; expand ratio embedding: [1 0 0] => expand ratio: 3
|

1
| <Figure size 1422.4x177.2 with 1 Axes>
|
1
| The accuracy of this subnet on the holdout validation set is: 88.7%.
|
Question 4 (10 pts): Complete the code for accuracy predictor training.
Now let’s train the accuracy predictor using the dataset we provided! In this part, you are responsible for the implementation of the training and validation of your accuracy predictor. The training process will take roughly 1-2 minutes.
Hint: you may refer to Tutorial 2 on how to train a neural network with PyTorch.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| criterion = torch.nn.L1Loss().to(device)
optimizer = torch.optim.Adam(acc_predictor.parameters())
# the default value is zero
acc_predictor.base_acc.data += base_acc
for epoch in tqdm(range(10)):
acc_predictor.train()
for (data, label) in tqdm(train_loader, desc="Epoch%d" % (epoch + 1), position=0, leave=True):
# step 1. Move the data and labels to device (cuda:0).
data = data.to(device)
label = label.to(device)
############### YOUR CODE STARTS HERE ###############
# step 2. Run forward pass.
pred = acc_predictor(data)
# step 3. Calculate the loss.
loss = criterion(pred, label)
# step 4. Perform the backward pass.
optimizer.zero_grad()
loss.backward()
optimizer.step()
################ YOUR CODE ENDS HERE ################
acc_predictor.eval()
with torch.no_grad():
with tqdm(total=len(valid_loader), desc="Val", position=0, leave=True) as t:
for (data, label) in valid_loader:
# step 1. Move the data and labels to device (cuda:0).
data = data.to(device)
label = label.to(device)
############### YOUR CODE STARTS HERE ###############
# step 2. Run forward pass.
pred = acc_predictor(data)
# step 3. Calculate the loss.
loss = criterion(pred, label)
############### YOUR CODE ENDS HERE ###############
t.set_postfix({"loss": loss.item()})
t.update(1)
if not os.path.exists(acc_pred_checkpoint_path):
torch.save(acc_predictor.cpu().state_dict(), acc_pred_checkpoint_path)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| Epoch1: 100%|██████████| 157/157 [00:01<00:00, 101.01it/s]
Val: 100%|██████████| 40/40 [00:00<00:00, 48.38it/s, loss=0.00264]
Epoch2: 100%|██████████| 157/157 [00:01<00:00, 117.19it/s]
Val: 100%|██████████| 40/40 [00:00<00:00, 48.89it/s, loss=0.00161]
Epoch3: 100%|██████████| 157/157 [00:01<00:00, 115.86it/s]
Val: 100%|██████████| 40/40 [00:00<00:00, 49.96it/s, loss=0.00226]
Epoch4: 100%|██████████| 157/157 [00:02<00:00, 77.42it/s]
Val: 100%|██████████| 40/40 [00:01<00:00, 37.70it/s, loss=0.00163]
Epoch5: 100%|██████████| 157/157 [00:01<00:00, 119.16it/s]
Val: 100%|██████████| 40/40 [00:00<00:00, 49.85it/s, loss=0.00174]
Epoch6: 100%|██████████| 157/157 [00:01<00:00, 122.14it/s]
Val: 100%|██████████| 40/40 [00:00<00:00, 49.41it/s, loss=0.00186]
Epoch7: 100%|██████████| 157/157 [00:01<00:00, 117.80it/s]
Val: 100%|██████████| 40/40 [00:00<00:00, 49.27it/s, loss=0.00148]
Epoch8: 100%|██████████| 157/157 [00:01<00:00, 117.19it/s]
Val: 100%|██████████| 40/40 [00:00<00:00, 49.47it/s, loss=0.0015]
Epoch9: 100%|██████████| 157/157 [00:01<00:00, 111.50it/s]
Val: 100%|██████████| 40/40 [00:01<00:00, 30.93it/s, loss=0.00132]
Epoch10: 100%|██████████| 157/157 [00:01<00:00, 89.64it/s]
Val: 100%|██████████| 40/40 [00:00<00:00, 48.22it/s, loss=0.00143]
100%|██████████| 10/10 [00:23<00:00, 2.37s/it]
|
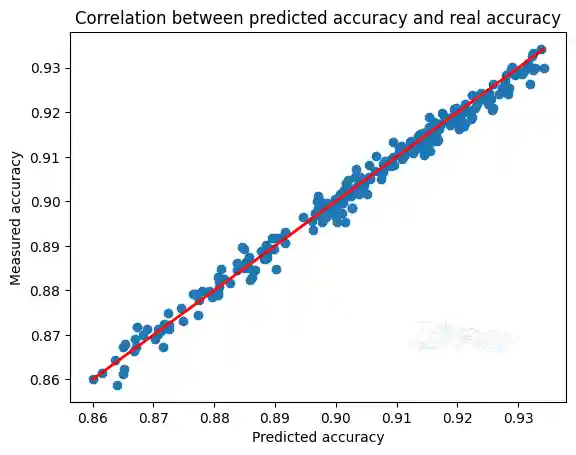
Now let’s plot the correlation of predicted accuracy against ground truth accuracy and make sure our predictor is reliable. To receive full score, you are expected to see a linear correlation in this part.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| predicted_accuracies = []
ground_truth_accuracies = []
acc_predictor = acc_predictor.to("cuda:0")
acc_predictor.eval()
with torch.no_grad():
with tqdm(total=len(valid_loader), desc="Val") as t:
for (data, label) in valid_loader:
data = data.to(device)
label = label.to(device)
pred = acc_predictor(data)
predicted_accuracies += pred.cpu().numpy().tolist()
ground_truth_accuracies += label.cpu().numpy().tolist()
if len(predicted_accuracies) > 200:
break
plt.scatter(predicted_accuracies, ground_truth_accuracies)
# draw y = x
min_acc, max_acc = min(predicted_accuracies), max(predicted_accuracies)
plt.plot([min_acc, max_acc], [min_acc, max_acc], c="red", linewidth=2)
plt.xlabel("Predicted accuracy")
plt.ylabel("Measured accuracy")
plt.title("Correlation between predicted accuracy and real accuracy")
|
1
| Val: 0%| | 0/40 [00:00<?, ?it/s]
|
1
| Text(0.5, 1.0, 'Correlation between predicted accuracy and real accuracy')
|
1
| <Figure size 640x480 with 1 Axes>
|
Part 2. Neural Architecture Search (6 Questions, 65 pts + 10 bonus pts)
So far, we have defined both the efficiency and accuracy predictors. Let’s start fast model specialization with these two powerful predictors!
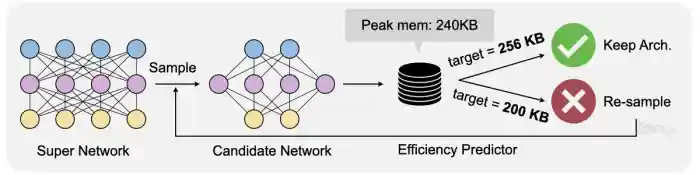
In this part, you are required to implement two typical search algorithms: random search and evolutionary search. The search algorithm aims to find the model architecture that provides the best accuracy while satisfying the efficiency constraints (e.g., MACs, peak memory).
Question 5 (5 pts): Complete the following random search agent.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| class RandomSearcher:
def __init__(self, efficiency_predictor, accuracy_predictor):
self.efficiency_predictor = efficiency_predictor
self.accuracy_predictor = accuracy_predictor
def random_valid_sample(self, constraint):
# randomly sample subnets until finding one that satisfies the constraint
while True:
sample = self.accuracy_predictor.arch_encoder.random_sample_arch()
efficiency = self.efficiency_predictor.get_efficiency(sample)
if self.efficiency_predictor.satisfy_constraint(efficiency, constraint):
return sample, efficiency
def run_search(self, constraint, n_subnets=100):
subnet_pool = []
# sample subnets
for _ in tqdm(range(n_subnets)):
sample, efficiency = self.random_valid_sample(constraint)
subnet_pool.append(sample)
# predict the accuracy of subnets
accs = self.accuracy_predictor.predict_acc(subnet_pool)
############### YOUR CODE STARTS HERE ###############
# hint: one line of code
# get the index of the best subnet
best_idx = accs.argmax()
############### YOUR CODE ENDS HERE #################
# return the best subnet
return accs[best_idx], subnet_pool[best_idx]
|
Question 6 (5 pts): Complete the following function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| def search_and_measure_acc(agent, constraint, **kwargs):
############### YOUR CODE STARTS HERE ###############
# hint: call the search function
best_info = agent.run_search(constraint=constraint, **kwargs)
############### YOUR CODE ENDS HERE #################
# get searched subnet
ofa_network.set_active_subnet(**best_info[1])
subnet = ofa_network.get_active_subnet().to(device)
# calibrate bn
calib_bn(subnet, data_dir, 128, best_info[1]["image_size"])
# build val loader
val_loader = build_val_data_loader(data_dir, best_info[1]["image_size"], 128)
# measure accuracy
acc = validate(subnet, val_loader)
# print best_info
print(f"Accuracy of the selected subnet: {acc}")
# visualize model architecture
visualize_subnet(best_info[1])
return acc, subnet
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| random.seed(1)
np.random.seed(1)
nas_agent = RandomSearcher(efficiency_predictor, acc_predictor)
# MACs-constrained search
subnets_rs_macs = {}
for millonMACs in [50, 100]:
search_constraint = dict(millonMACs=millonMACs)
print(f"Random search with constraint: MACs <= {millonMACs}M")
subnets_rs_macs[millonMACs] = search_and_measure_acc(nas_agent, search_constraint, n_subnets=300)
# memory-constrained search
subnets_rs_memory = {}
for KBPeakMemory in [256, 512]:
search_constraint = dict(KBPeakMemory=KBPeakMemory)
print(f"Random search with constraint: Peak memory <= {KBPeakMemory}KB")
subnets_rs_memory[KBPeakMemory] = search_and_measure_acc(nas_agent, search_constraint, n_subnets=300)
|
1
| Random search with constraint: MACs <= 50M
|
1
2
| 100%|██████████| 300/300 [01:06<00:00, 4.49it/s]
Validate: 100%|██████████| 32/32 [00:08<00:00, 3.60it/s, loss=0.187, top1=93.3]
|
1
| Accuracy of the selected subnet: 93.27543427346657
|

1
| <Figure size 1630.4x177.2 with 1 Axes>
|
1
| Random search with constraint: MACs <= 100M
|
1
2
| 100%|██████████| 300/300 [01:06<00:00, 4.50it/s]
Validate: 100%|██████████| 32/32 [00:09<00:00, 3.46it/s, loss=0.188, top1=93.5]
|
1
| Accuracy of the selected subnet: 93.5483871270646
|

1
| <Figure size 1630.4x177.2 with 1 Axes>
|
1
| Random search with constraint: Peak memory <= 256KB
|
1
2
| 100%|██████████| 300/300 [02:24<00:00, 2.08it/s]
Validate: 100%|██████████| 32/32 [00:10<00:00, 3.17it/s, loss=0.206, top1=92.8]
|
1
| Accuracy of the selected subnet: 92.77915630482562
|

1
| <Figure size 1561.2x177.2 with 1 Axes>
|
1
| Random search with constraint: Peak memory <= 512KB
|
1
2
| 100%|██████████| 300/300 [01:12<00:00, 4.11it/s]
Validate: 100%|██████████| 32/32 [00:10<00:00, 3.11it/s, loss=0.19, top1=93.2]
|
1
| Accuracy of the selected subnet: 93.15136479455839
|

1
| <Figure size 1561.2x177.2 with 1 Axes>
|
Question7 (20 pts): Complete the following evolutionary search agent.

Now you have succesfully implemented the random search algorithm. In this part, we will implement a more sample-efficient search algorithm, evolutionary search. Evolutionary search is inspired by the evolution algorithm (or genetic algorithm). A population of sub-networks are first sampled from the design space. Then, in each generation, we perform random mutation and crossover operations as is shown in the figure above. The sub-networks with highest accuracy will be kept, and this process will be repeated until the number of generations reaches max_time_budget. Similar to the random search, throughout the search process, all sub-networks that cannot satisfy the efficiency constraint will be discarded.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
| class EvolutionSearcher:
def __init__(self, efficiency_predictor, accuracy_predictor, **kwargs):
self.efficiency_predictor = efficiency_predictor
self.accuracy_predictor = accuracy_predictor
# evolution hyper-parameters
self.arch_mutate_prob = kwargs.get("arch_mutate_prob", 0.1)
self.resolution_mutate_prob = kwargs.get("resolution_mutate_prob", 0.5)
self.population_size = kwargs.get("population_size", 100)
self.max_time_budget = kwargs.get("max_time_budget", 500)
self.parent_ratio = kwargs.get("parent_ratio", 0.25)
self.mutation_ratio = kwargs.get("mutation_ratio", 0.5)
def update_hyper_params(self, new_param_dict):
self.__dict__.update(new_param_dict)
def random_valid_sample(self, constraint):
# randomly sample subnets until finding one that satisfies the constraint
while True:
sample = self.accuracy_predictor.arch_encoder.random_sample_arch()
efficiency = self.efficiency_predictor.get_efficiency(sample)
if self.efficiency_predictor.satisfy_constraint(efficiency, constraint):
return sample, efficiency
def mutate_sample(self, sample, constraint):
while True:
new_sample = copy.deepcopy(sample)
self.accuracy_predictor.arch_encoder.mutate_resolution(new_sample, self.resolution_mutate_prob)
self.accuracy_predictor.arch_encoder.mutate_width(new_sample, self.arch_mutate_prob)
self.accuracy_predictor.arch_encoder.mutate_arch(new_sample, self.arch_mutate_prob)
efficiency = self.efficiency_predictor.get_efficiency(new_sample)
if self.efficiency_predictor.satisfy_constraint(efficiency, constraint):
return new_sample, efficiency
def crossover_sample(self, sample1, sample2, constraint):
while True:
new_sample = copy.deepcopy(sample1)
for key in new_sample.keys():
if not isinstance(new_sample[key], list):
############### YOUR CODE STARTS HERE ###############
# hint: randomly choose the value from sample1[key] and sample2[key], random.choice
new_sample[key] = random.choice([sample1[key], sample2[key]])
############### YOUR CODE ENDS HERE #################
else:
for i in range(len(new_sample[key])):
############### YOUR CODE STARTS HERE ###############
new_sample[key][i] = random.choice([sample1[key][i], sample2[key][i]])
############### YOUR CODE ENDS HERE #################
efficiency = self.efficiency_predictor.get_efficiency(new_sample)
if self.efficiency_predictor.satisfy_constraint(efficiency, constraint):
return new_sample, efficiency
def run_search(self, constraint, **kwargs):
self.update_hyper_params(kwargs)
mutation_numbers = int(round(self.mutation_ratio * self.population_size))
parents_size = int(round(self.parent_ratio * self.population_size))
best_valids = [-100]
population = [] # (acc, sample) tuples
child_pool = []
best_info = None
# generate random population
for _ in range(self.population_size):
sample, efficiency = self.random_valid_sample(constraint)
child_pool.append(sample)
accs = self.accuracy_predictor.predict_acc(child_pool)
for i in range(self.population_size):
population.append((accs[i].item(), child_pool[i]))
# evolving the population
with tqdm(total=self.max_time_budget) as t:
for i in range(self.max_time_budget):
############### YOUR CODE STARTS HERE ###############
# hint: sort the population according to the acc (descending order)
population = sorted(population, key=lambda x: x[0], reverse=True)
############### YOUR CODE ENDS HERE #################
############### YOUR CODE STARTS HERE ###############
# hint: keep topK samples in the population, K = parents_size
# the others are discarded.
population = population[:parents_size]
############### YOUR CODE ENDS HERE #################
# update best info
acc = population[0][0]
if acc > best_valids[-1]:
best_valids.append(acc)
best_info = population[0]
else:
best_valids.append(best_valids[-1])
child_pool = []
for j in range(mutation_numbers):
# randomly choose a sample
par_sample = population[np.random.randint(parents_size)][1]
# mutate this sample
new_sample, efficiency = self.mutate_sample(par_sample, constraint)
child_pool.append(new_sample)
for j in range(self.population_size - mutation_numbers):
# randomly choose two samples
par_sample1 = population[np.random.randint(parents_size)][1]
par_sample2 = population[np.random.randint(parents_size)][1]
# crossover
new_sample, efficiency = self.crossover_sample(
par_sample1, par_sample2, constraint
)
child_pool.append(new_sample)
# predict accuracy with the accuracy predictor
accs = self.accuracy_predictor.predict_acc(child_pool)
for j in range(self.population_size):
population.append((accs[j].item(), child_pool[j]))
t.update(1)
return best_info
|
Question 8 (10pts): Run evolutionary search and tune evo_params to optimize the results. Describe your findings.
Answer:
- The default population size and time budget are too small. Increasing them (e.g.,
population_size=50, max_time_budget=20) improves results but increases search cost (~4 min per search in our run). - Increasing
resolution_mutate_prob to 0.5 helps, consistent with Question 1. With tuned params, evolutionary search reached ~92.3–93.6% validation accuracy under MAC/memory constraints (e.g., 92.3% at ≤50M MACs, 93.6% at ≤512KB peak memory).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| random.seed(1)
np.random.seed(1)
# hint: tune hyper-parameters below
evo_params = {
'arch_mutate_prob': 0.1, # The probability of architecture mutation in evolutionary search
'resolution_mutate_prob': 0.5, # The probability of resolution mutation in evolutionary search
'population_size': 50, # The size of the population
'max_time_budget': 20,
'parent_ratio': 0.25,
'mutation_ratio': 0.3,
}
nas_agent = EvolutionSearcher(efficiency_predictor, acc_predictor, **evo_params)
# MACs-constrained search
subnets_evo_macs = {}
for millonMACs in [50, 100]:
search_constraint = dict(millionMACs=millonMACs)
print(f"Evolutionary search with constraint: MACs <= {millonMACs}M")
subnets_evo_macs[millonMACs] = search_and_measure_acc(nas_agent, search_constraint)
# memory-constrained search
subnets_evo_memory = {}
for KBPeakMemory in [256, 512]:
search_constraint = dict(KBPeakMemory=KBPeakMemory)
print(f"Evolutionary search with constraint: Peak memory <= {KBPeakMemory}KB")
subnets_evo_memory[KBPeakMemory] = search_and_measure_acc(nas_agent, search_constraint)
|
1
| Evolutionary search with constraint: MACs <= 50M
|
1
2
| 100%|██████████| 20/20 [04:13<00:00, 12.66s/it]
Validate: 100%|██████████| 32/32 [00:09<00:00, 3.54it/s, loss=0.209, top1=92.3]
|
1
| Accuracy of the selected subnet: 92.25806454641943
|

1
| <Figure size 1422.4x177.2 with 1 Axes>
|
1
| Evolutionary search with constraint: MACs <= 100M
|
1
2
| 100%|██████████| 20/20 [04:11<00:00, 12.57s/it]
Validate: 100%|██████████| 32/32 [00:10<00:00, 3.18it/s, loss=0.19, top1=92.9]
|
1
| Accuracy of the selected subnet: 92.92803973252366
|

1
| <Figure size 1422.4x177.2 with 1 Axes>
|
1
| Evolutionary search with constraint: Peak memory <= 256KB
|
1
2
| 100%|██████████| 20/20 [04:21<00:00, 13.08s/it]
Validate: 100%|██████████| 32/32 [00:08<00:00, 3.62it/s, loss=0.196, top1=92.8]
|
1
| Accuracy of the selected subnet: 92.75434240904399
|

1
| <Figure size 1699.6x177.2 with 1 Axes>
|
1
| Evolutionary search with constraint: Peak memory <= 512KB
|
1
2
| 100%|██████████| 20/20 [04:12<00:00, 12.60s/it]
Validate: 100%|██████████| 32/32 [00:09<00:00, 3.43it/s, loss=0.187, top1=93.6]
|
1
| Accuracy of the selected subnet: 93.6228288144095
|

1
| <Figure size 1630.4x177.2 with 1 Axes>
|
Question 9 (15 pts + 10 pts bonus): Run evolutionary search under real-world constraints.
In real-world applications, we may have multiple efficiency constraints: https://blog.tensorflow.org/2019/10/visual-wake-words-with-tensorflow-lite_30.html.
Use evolutionary search to find models that satisfy the following constraints:
- [15 pts] 250 KB, 60M MACs (acc >= 92.5% to get the full credit)
- [10 pts, bonus] 200KB, 30M MACs (acc >= 90% to get the full credit)
Hint: You do not have to use the same evo_params for these two tasks.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| random.seed(1)
np.random.seed(1)
# hint: tune hyper-parameters below
evo_params = {
'arch_mutate_prob': 0.1, # The probability of architecture mutation in evolutionary search
'resolution_mutate_prob': 0.5, # The probability of resolution mutation in evolutionary search
'population_size': 50, # The size of the population
'max_time_budget': 20,
'parent_ratio': 0.25,
'mutation_ratio': 0.3,
}
nas_agent = EvolutionSearcher(efficiency_predictor, acc_predictor, **evo_params)
(millionMACs, KBPeakMemory) = [60, 250]
print(f"Evolution search with constraint: MACs <= {millionMACs}M, peak memory <= {KBPeakMemory}KB")
search_and_measure_acc(nas_agent, dict(millionMACs=millionMACs, KBPeakMemory=KBPeakMemory))
print("Evolution search finished!")
|
1
| Evolution search with constraint: MACs <= 60M, peak memory <= 250KB
|
1
2
| 100%|██████████| 20/20 [04:32<00:00, 13.65s/it]
Validate: 100%|██████████| 32/32 [00:09<00:00, 3.24it/s, loss=0.203, top1=92.7]
|
1
| Accuracy of the selected subnet: 92.72952851326235
|

1
| <Figure size 1561.2x177.2 with 1 Axes>
|
1
| Evolution search finished!
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| random.seed(1)
np.random.seed(1)
# hint: tune hyper-parameters below
evo_params = {
'arch_mutate_prob': 0.1, # The probability of architecture mutation in evolutionary search
'resolution_mutate_prob': 0.5, # The probability of resolution mutation in evolutionary search
'population_size': 50, # The size of the population
'max_time_budget': 30,
'parent_ratio': 0.25,
'mutation_ratio': 0.3,
}
nas_agent = EvolutionSearcher(efficiency_predictor, acc_predictor, **evo_params)
(millionMACs, KBPeakMemory) = [30, 200]
print(f"Evolution search with constraint: MACs <= {millionMACs}M, peak memory <= {KBPeakMemory}KB")
search_and_measure_acc(nas_agent, dict(millionMACs=millionMACs, KBPeakMemory=KBPeakMemory))
print("Evolution search finished!")
|
1
| Evolution search with constraint: MACs <= 30M, peak memory <= 200KB
|
1
2
| 100%|██████████| 30/30 [05:51<00:00, 11.71s/it]
Validate: 100%|██████████| 32/32 [00:07<00:00, 4.02it/s, loss=0.248, top1=90.5]
|
1
| Accuracy of the selected subnet: 90.47146403878261
|

1
| <Figure size 1353.2x177.2 with 1 Axes>
|
1
| Evolution search finished!
|
Question 10 (10 pts): Is it possible to find a subnet with the following efficiency constraints in the current design space?
- A: The activation size of the subnet is at most 256KB and the MACs of the subnet is at most 15M.
- B: The activation size of the subnet is at most 64 KB.
Answer:
- A (≤256 KB activation, ≤15M MACs): Yes. The smallest subnet in the design space uses ~8.3M MACs and ~72 KB peak activation (within both limits) and achieves ~83.4% accuracy at 96×96.
- B (≤64 KB activation): No. Even the smallest subnet has ~72 KB peak activation, which already exceeds the 64 KB limit, so no feasible subnet exists in this design space.